I've had several enquires seeking more details about version 2.0 of cqrs.net, and found myself sharing the same details, so here's some further details.
Currently cqrs.net is two things. Firstly a core framework to provide a solid
structure to build on in pretty much any way you want to. Secondly, it is some tooling to
remove a lot of hand written code IF you want to have a strong domain driven design (DDD) structure over
the top of a CQRS base. This is an important point. As with all software there are compromises, be it architecture, maintainability, technical debt, ease of support or deployment.
Given most of DDD is repetition in the form of creating classes that follow
a certain set of rules and patterns to create separation and order, much of what
a developer ends up coding (time their fingers are on the keyboard) isn't
actually coding the problem solving code... it's creating the structure for the
separation.
Currently our tooling tackles this issue by
allowing you to define (using UML) your commands, events, aggregates, queries
and some thin façade services to provide public access to these generally
internal concepts. Once defined, you can use the code generation built into our
tooling to have the scaffold of all your classes created for you. Literally all
you need to code is the actual business logic itself... usually some form of if
or switch statement that asserts some condition and then publishes an event.
Really this is what developers do when you take away the need to code structure
- obviously there are things like calling third party services and sending
emails or communicating with firmware, but basic process and work-flow control
should be fast.
While writing our documentation, it really hit home
how crude and basic our tooling was, just look at our first attempt
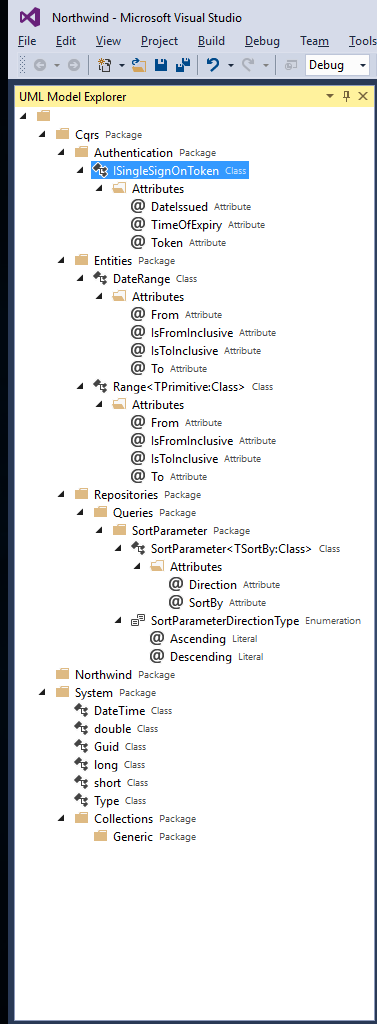 at https://github.com/Chinchilla-Software-Com/CQRS/wiki/Tutorial-0:-Quick-Northwind-sample. It's all branch, node and leaf based in a tree... not
really that visual.
at https://github.com/Chinchilla-Software-Com/CQRS/wiki/Tutorial-0:-Quick-Northwind-sample. It's all branch, node and leaf based in a tree... not
really that visual.
What version 2.0 is focused on is taking our tooling to the next step by adding
visual work-flows, similar to what is seen in the blog post

https://cqrs-net.blogspot.co.nz/2016/10/version-20.html. This means you can drop a command, aggregate and several events onto a visual view and connect them together to define in a visual way that we start with this command, that will be handled by this aggregate, and return one or more of the following events.
https://cqrs-net.blogspot.co.nz/2016/10/version-20.html. This means you can drop a command, aggregate and several events onto a visual view and connect them together to define in a visual way that we start with this command, that will be handled by this aggregate, and return one or more of the following events.
From there the code generation will create your scaffold, again leaving
only the code of reading the incoming command, doing whatever if/switch logic and
depending on the path chosen publish the event(s) needed. The advantage here
being that less technical people can be involved in the process of defining what
the work-flow should do. This then becomes a promise from the development team
that this is what you all agree on to be done. Other possible work-flows are
out of scope (to be done later probably) - thus scope creep is avoided and unintentional work-flow changes
don't occur. If you do need to be agile and modify the work-flow, the
consequences of doing so are very visually apparent and easily spotted. This
will all be backwards compatible with our existing tooling, so if you started
with the branch/node/leaf based tooling you won't be wasting time. You'll be
able to use which ever part of the tooling is most suitable to you and your
needs at the time.
With version 2.0 we also aim have our akka.net modules supported - we're currently
still testing and developing the module as the akka.net project
moves forward into a production ready state.
We already have some improvements around simpler implementations of event
and data stores using SQL and more Azure service-bus options (EventHubs and
topics will be supported out of the box).
Version 3 is where we'll be redefining some internal workings for the tooling (a
simple migration path is a requirement so this might take some time) to prepare
us for our future development which includes .net core. So this would be the
earliest you'll see .net core being active on our road map. We're also very dependant on our third party dependencies, like Azure and MongoDB.

